

一、背景介绍
felx-job是内部基于xxl-job二开的分布式定时任务平台,提供部门统一的定时任务管理。某次反馈查询任务列表慢。
使用arthas的trace命令查看耗时
trace com.xxl.job.admin.service.XxlJobService queryJobs
耗时:4600ms+

二、分析过程
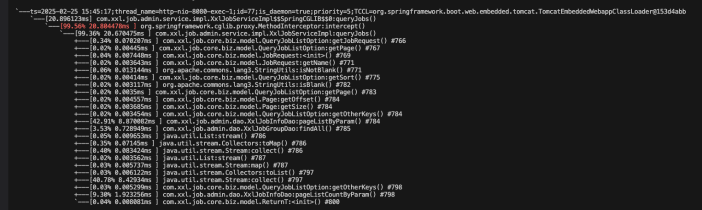
1、看上图trace结果,发现时间对不上,是因为有些类和函数未被trace追踪到,比如jdk的方法,加上不忽略jdk方法
trace --skipJDKMethod false com.xxl.job.admin.service.impl.XxlJobServiceImpl queryJobs -n 5
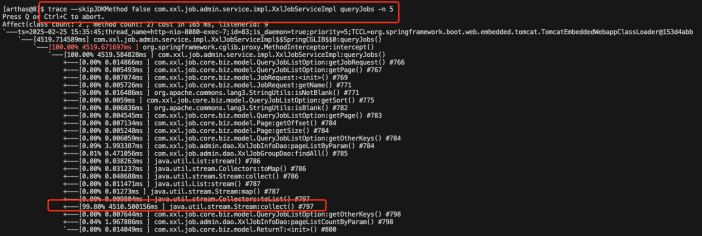
3、然后发现是stream耗时,查看代码,是流中循环查日志表xxl_job_log表耗时久
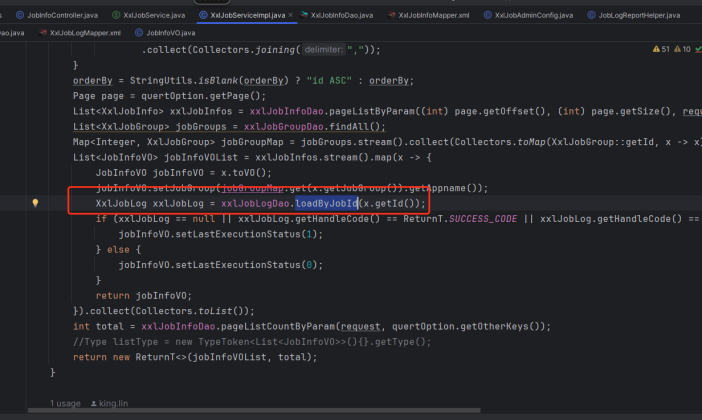
根据job_id查询且根据id排序
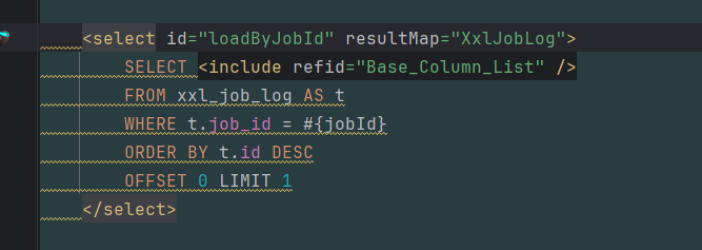
4、xxl_job_log日志表会很大几天就可能有千万数据
三、优化
添加job_id和id的联合索引优化
CREATE INDEX "I_job_id" ON "xxl_job_log" USING btree (
"job_id",
"id"
);
耗时降到20ms+,此时日志表数据50w左右,结合xxl_job中配置日志保留7天,后续应该不会有性能问题
评论区