

JVM 的操作对象是 Class 文件,JVM 把 Class 文件中描述类的数据结构加载到内存中,并对数据进行校验、解析和初始化,最终转化成可以被 JVM 直接使用的类型,这个过程被称为类加载机制。
其中最重要的三个概念就是:类加载器、类加载过程和双亲委派模型。
类加载器:负责加载类文件,将类文件加载到内存中,生成 Class 对象。
类加载过程:包括加载、验证、准备、解析和初始化等步骤。
双亲委派模型:当一个类加载器接收到类加载请求时,它会把请求委派给父——类加载器去完成,依次递归,直到最顶层的类加载器,如果父——类加载器无法完成加载请求,子类加载器才会尝试自己去加载。
一、四种类加载器
①、启动类加载器
负责加载 JVM 的核心类库,如 rt.jar 和其他核心库位于JAVA_HOME/jre/lib目录下的类。
②、扩展类加载器
负责加载JAVA_HOME/jre/lib/ext目录下,或者由系统属性java.ext.dirs指定位置的类库,由sun.misc.Launcher$ExtClassLoader 实现。
③、应用程序类加载器
负责加载 classpath 的类库,由sun.misc.Launcher$AppClassLoader实现。
我们编写的任何类都是由应用程序类加载器加载的,除非显式使用自定义类加载器。
④、用户自定义类加载器
通常用于加载网络上的类、执行热部署(动态加载和替换应用程序的组件),或者为了安全考虑,从不同的源加载类。
二、类的生命周期
一个类从被加载到虚拟机内存中开始,到从内存中卸载,整个生命周期需要经过七个阶段:加载 、验证、准备、解析、初始化、使用和卸载。
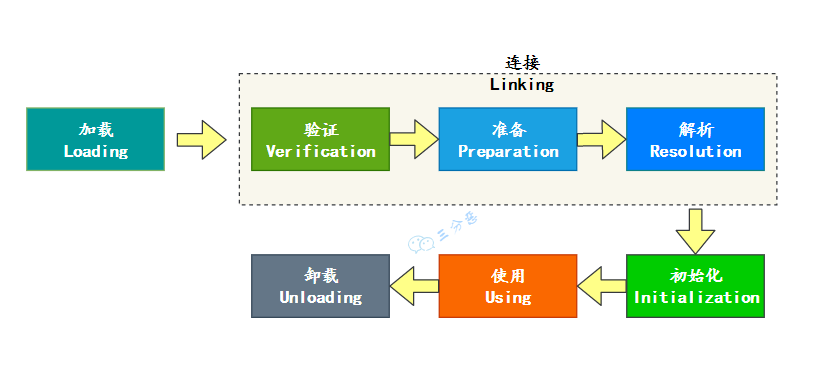
类装载过程包括三个阶段:载入、链接和初始化。
①、载入:将类的二进制字节码加载到内存中。
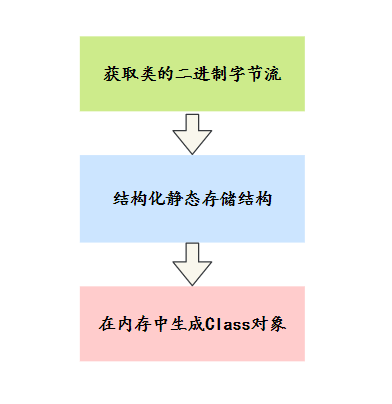
1)通过一个类的全限定名来获取定义此类的二进制字节流。
2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
3)在内存中生成一个代表这个类的 java.lang.Class 对象,作为这个类的访问入口。
②、链接可以细分为三个小的阶段:
验证:检查类文件格式是否符合 JVM 规范
准备:为类的静态变量分配内存并设置默认值。
解析:将符号引用替换为直接引用。
③、初始化:执行静态代码块和静态变量初始化。
在准备阶段,静态变量已经被赋过默认初始值了,在初始化阶段,静态变量将被赋值为代码期望赋的值。比如说 static int a = 1;,在准备阶段,a 的值为 0,在初始化阶段,a 的值为 1。
三、双亲委派机制
当某个类加载器需要加载某个.class文件时,它首先把这个任务委托给他的上级类加载器,递归这个操作,如果上级的类加载器没有加载,自己才会去加载这个类。如果所有加载器都无法加载这个类,最终抛出 ClassNotFoundException
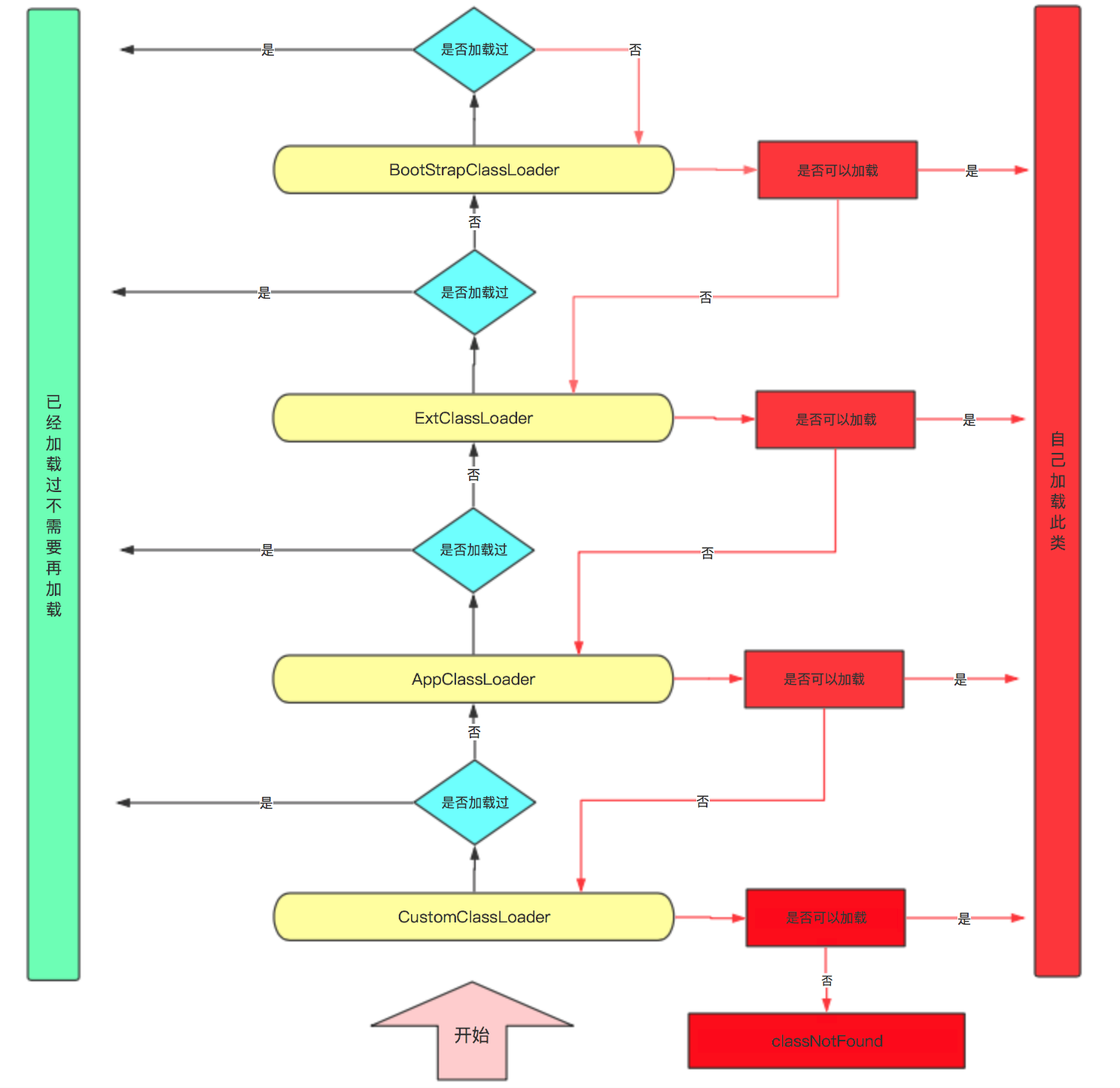
为什么要用双亲委派模型?
①、避免类的重复加载:父加载器加载的类,子加载器无需重复加载。
②、保证核心类库的安全性:如 java.lang.* 只能由 Bootstrap ClassLoader 加载,防止被篡改。
四、破坏双亲委派机制
1、重写 ClassLoader 的 loadClass() 方法。
2、如果不想打破双亲委派模型,就重写 ClassLoader 类中的 findClass() 方法,那些无法被父类加载器加载的类最终会通过这个方法被加载。
例子
1、SPI 机制加载 JDBC 驱动
SPI 是 Java 的一种扩展机制,用于加载和注册第三方类库,常见于 JDBC、JNDI 等框架。
双亲委派模型会优先让父类加载器加载类,而 SPI 需要动态加载子类加载器中的实现。
根据双亲委派模型,java.sql.Driver 类应该由父加载器加载,但父类加载器无法加载由子类加载器定义的驱动类,如 MySQL 的 com.mysql.cj.jdbc.Driver。
那么只能使用 SPI 机制通过 META-INF/services 文件指定服务提供者的实现类。
ClassLoader cl = Thread.currentThread().getContextClassLoader();
Enumeration<Driver> drivers = ServiceLoader.load(Driver.class, cl).iterator();DriverManager 使用了线程上下文类加载器来加载 SPI 的实现类,从而允许子类加载器加载具体的 JDBC 驱动。
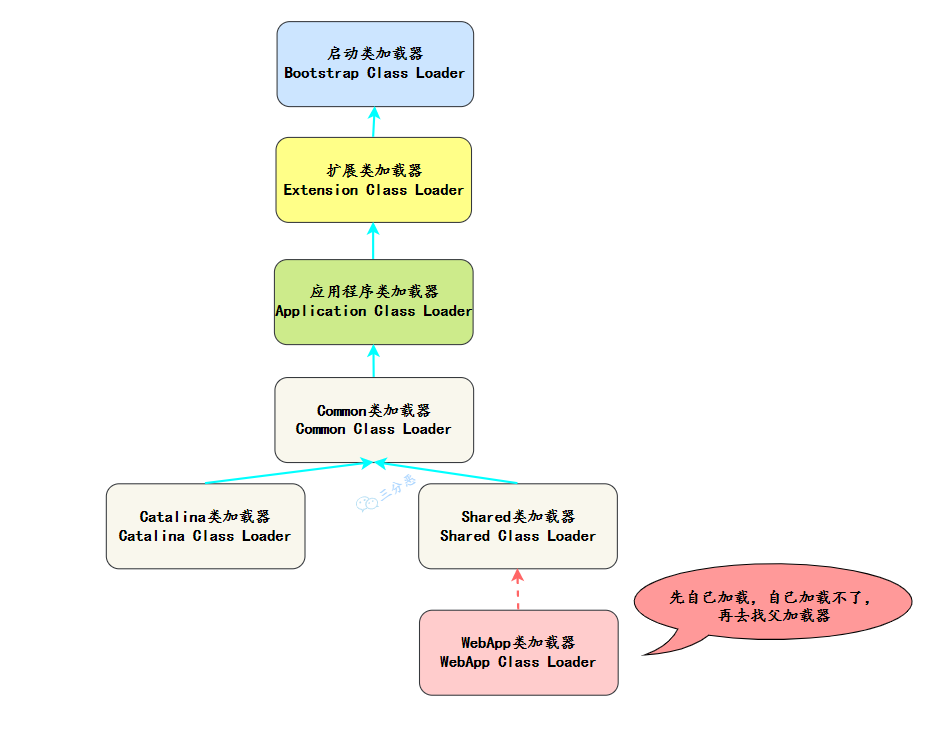
2、tomcat类加载机制
Tomcat 基于双亲委派模型进行了一些扩展,主要的类加载器有:
BootstrapClassLoader:加载 Java 的核心类库;
CatalinaClassLoader:加载 Tomcat 的核心类库;
SharedClassLoader:加载共享类库,允许多个 Web 应用共享某些类库;
WebAppClassLoader:加载 Web 应用程序的类库,支持多应用隔离和优先加载应用自定义的类库(破坏了双亲委派模型)。
3、热部署框架
热部署是指在不重启服务器的情况下更新应用程序代码,需要替换旧版本的类,但旧版本的类可能由父加载器加载。
如 Spring Boot 的 DevTools 通常会自定义类加载器,优先加载新的类版本。
实现自己的热部署:需要在类加载器的基础上,实现类的重新加载。
第一步,使用文件监控机制,如 Java NIO 的 WatchService 来监控类文件或配置文件的变化。当监控到文件变更时,触发热部署流程。
class FileWatcher {
public static void watchDirectoryPath(Path path) {
// 检查路径是否是有效目录
if (!isDirectory(path)) {
System.err.println("Provided path is not a directory: " + path);
return;
}
System.out.println("Starting to watch path: " + path);
// 获取文件系统的 WatchService
try (WatchService watchService = path.getFileSystem().newWatchService()) {
// 注册目录监听服务,监听创建、修改和删除事件
path.register(watchService, ENTRY_CREATE, ENTRY_MODIFY, ENTRY_DELETE);
while (true) {
WatchKey key;
try {
// 阻塞直到有事件发生
key = watchService.take();
} catch (InterruptedException e) {
System.out.println("WatchService interrupted, stopping directory watch.");
Thread.currentThread().interrupt();
break;
}
// 处理事件
for (WatchEvent<?> event : key.pollEvents()) {
processEvent(event);
}
// 重置 key,如果失败则退出
if (!key.reset()) {
System.out.println("WatchKey no longer valid. Exiting watch loop.");
break;
}
}
} catch (IOException e) {
System.err.println("An error occurred while setting up the WatchService: " + e.getMessage());
e.printStackTrace();
}
}
private static boolean isDirectory(Path path) {
return Files.isDirectory(path, LinkOption.NOFOLLOW_LINKS);
}
private static void processEvent(WatchEvent<?> event) {
WatchEvent.Kind<?> kind = event.kind();
// 处理事件类型
if (kind == OVERFLOW) {
System.out.println("Event overflow occurred. Some events might have been lost.");
return;
}
@SuppressWarnings("unchecked")
Path fileName = ((WatchEvent<Path>) event).context();
System.out.println("Event: " + kind.name() + ", File affected: " + fileName);
}
public static void main(String[] args) {
// 设置监控路径为当前目录
Path pathToWatch = Paths.get(".");
watchDirectoryPath(pathToWatch);
}
}第二步,创建一个自定义类加载器,继承java.lang.ClassLoader,并重写findClass()方法,用来加载新的类文件。
class HotSwapClassLoader extends ClassLoader {
public HotSwapClassLoader() {
super(ClassLoader.getSystemClassLoader());
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 加载指定路径下的类文件字节码
byte[] classBytes = loadClassData(name);
if (classBytes == null) {
throw new ClassNotFoundException(name);
}
// 调用defineClass将字节码转换为Class对象
return defineClass(name, classBytes, 0, classBytes.length);
}
private byte[] loadClassData(String name) {
// 实现从文件系统或其他来源加载类文件的字节码
// ...
return null;
}
}五、编译执行与解释执行
解释和编译的区别:
解释:将源代码逐行转换为机器码。
编译:将源代码一次性转换为机器码。
解释执行和编译执行的区别:
解释执行:程序运行时,将源代码逐行转换为机器码,然后执行。
编译执行:程序运行前,将源代码一次性转换为机器码,然后执行。
Java 一般被称为“解释型语言”
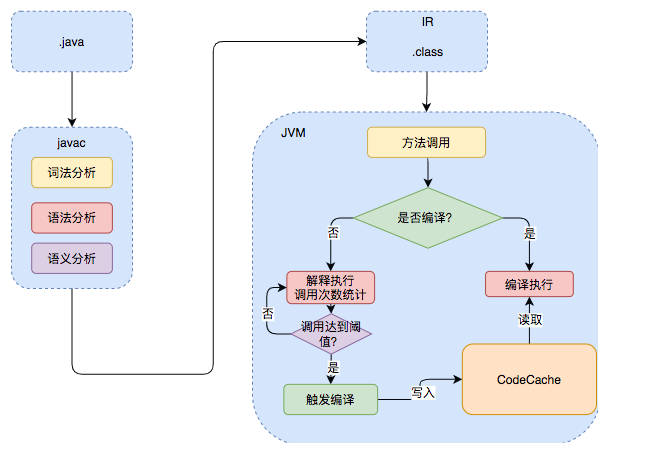
因为 Java 代码在执行前,需要先将源代码编译成字节码,然后在运行时,再由 JVM 的解释器“逐行”将字节码转换为机器码,然后执行。
这也是 Java 被诟病“慢”的主要原因。
但 JIT(just-in-time) 的出现打破了这种刻板印象,JVM 会将热点代码(即运行频率高的代码)编译后放入 CodeCache,当下次执行再遇到这段代码时,会从 CodeCache 中直接读取机器码,然后执行。
JVM通过两种主要技术来检测热点代码:基于采样的热点探测和基于计数器的热点探测。
1、基于采样的热点探测
这种方法通过周期性地检查各个线程的栈顶,如果某些方法经常出现在栈顶,则认为这些方法是热点方法。
2、基于计数器的热点探测
这种方法为每个方法或代码块建立计数器,统计其执行次数。如果执行次数超过一定的阈值,则认为它是热点方法。在HotSpot虚拟机中,使用的是基于计数器的热点探测方法。
因此,Java 的执行效率得到了大幅提升。
评论区